

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Improvements in computer vision and machine learning are making it harder for companies to defend against automated attacks.
4 Min Read
<p style="text-align:left">(Image: Google)</p>

10 Top Tech Companies Poised For Massive Layoffs
10 Top Tech Companies Poised For Massive Layoffs (Click image for larger view and slideshow.)
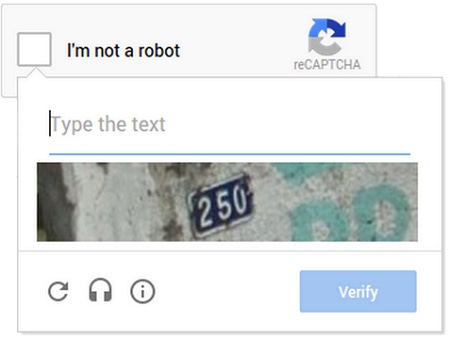
The term CAPTCHA, proposed by computer science researchers in 2000, stands for "Completely Automated Public Turing test to tell Computers and Humans Apart."
The Turing test, formulated by Alan Turing in 1950, attempts to evaluate whether a computer's conversational responses to questions can be distinguished from a person's answers.
A CAPTCHA represents a reverse Turing test because it asks a computer rather than a person to identify whether the respondent is human or machine. The roles are reversed.
Such tests are themselves being tested by recent advances in computer vision and machine learning. As Google recently demonstrated with AlphaGo, its Go-playing deep learning system, computer thinking rivals human thinking in a growing number of areas. And as the line between human and machine intelligence blurs, CAPTCHAs fail.
In a presentation at Black Hat Asia last month, Columbia University researchers Iasonas (Jason) Polakis and Suphannee Sivakorn described work they'd done with associate professor Angelos Keromytis to create an automated system to bypass CAPTCHAs used by Google and Facebook. The two companies, like others, rely on CAPTCHAs as a means of limiting fake account creation, spam posts, and other abuse of online services.
"Our system is extremely effective, automatically solving 70.78% of the image reCAPTCHA challenges, while requiring only 19 seconds per challenge," the researchers explain in a paper documenting their work. "We also apply our attack to the Facebook image CAPTCHA and achieve an accuracy of 83.5%."
Attacks on CAPTCHA systems have been an issue for years. When Google bought reCAPTCHA in 2009, the company hoped the technology would give it an edge in combating automated fraud. And for a time, it did.
But machines keep getting smarter. Advances in optical character recognition have made text-based CAPTCHAs all but unusable. CAPTCHA letters now have to be so distorted to fool the machines that people can't read them either. Google's latest iteration of reCAPTCHA alludes to the illegibility of recent CAPTCHA challenges in its marketing tagline: "Tough on bots, Easy on humans."
The researchers disclosed their work to Google, which has already implemented some counter-measures, and to Facebook.
"We're regularly in touch with the security research community and we appreciate their contributions to the safety of reCAPTCHA and other Google products," a Google spokesperson said in an emailed statement. "The Columbia University researchers notified us about this issue in May 2015 and we've since strengthened reCAPTCHA's protections based on their findings and our own studies."
In an email, Polakis describes CAPTCHA research as an example of a security arms race in which defenses get compromised and then hardened, only to be overcome again.
But in the past few years, Polakis said, advances in generic solvers against text CAPTCHAs have made distorted text challenges obsolete. Researchers have turned to more advanced tasks like extracting semantic information from images, as Google has done with its most recent reCAPTCHA system.
Google also looks at browser settings and user-agent data to determine the kind of CAPTCHA challenge it should present. These observable characteristics may help companies keep one step ahead of the bots, for a while at least.
Polakis says that the novel attacks his colleagues and he have developed underscore the difficulty facing those trying to design functional CAPTCHAs.
![]()
Gain insight into the latest threats and emerging best practices for managing them. Attend the Security Track at Interop Las Vegas, May 2-6. Register now!
"We believe that the capabilities of computer vision and machine learning have finally reached the point where expectations of automatically distinguishing between humans and bots with existing CAPTCHA schemes, without excluding a considerable number of legitimate users in the process, seem unrealistic," Polakis wrote. "As these capabilities can only improve, it will become even more difficult to devise CAPTCHAs that can withstand automated attacks."
Polakis is careful not to declare "game over," noting that CAPTCHAs remain an open problem and that alternative directions in research may allow CAPTCHAs to survive.
Google has revised its approach to CAPTCHAs numerous times over the past seven years. But there may come a point when machines become so perceptive and analytically capable that we will be able to create bots that pass any automated test we create.
(Editor's Note: Black Hat Asia is produced by UBM, InformationWeek's parent company.)

About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now