

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Customers are constantly asking Amazon to help them accomplish more in less time at lower costs. Amazon CEO Andy Jassy said the company is listening. Here’s what AWS presented as proof.
11 Min Read
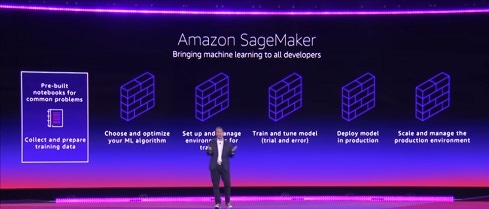
Photo by Lisa Morgan
Amazon plans to stay ahead of the IaaS/PaaS provider pack by out-innovating its competitors. On Wednesday, CEO Andy Jassy made a long string of product announcements in his AWS re:Invent keynote presentation intended to demonstrate that the company is listening to and acting upon what AWS customers want.
Not surprisingly, many of the day’s announcements focused on machine learning, although there were others spanning analytics, compute, databases, security, storage and more. Following is a recap of what was announced and why the new offerings are important.
Analytics
When Jassy mentioned data lakes, the audience groaned. Here’s why: Data lakes are difficult and time-consuming to set up and manage. The entire end-to-end process involves loading data from diverse sources, monitoring the data flows, setting up partitions, turning on encryption and managing keys, defining transformation jobs and monitoring their operation, re-organizing data into a columnar format, configuring access control settings, deduplicating redundant data, matching linked records, granting access to data sets, and auditing access over time. AWS Lake Formation allows users to set up a secure data lake relatively easily in a matter of days.
Users simply declare where the data resides and tell the service which data access and security policies should be applied. AWS Lake Formation then collects and catalogs data from databases and object stores, moves the data into a new Amazon S3 data lake, cleans and classifies data using machine learning algorithms, and secures access to sensitive data. End users can then access a centralized data catalog that describes the available data sets and their appropriate use.
Compute
Enterprises have made it clear that hybrid cloud solutions shouldn’t require different IT and development environments for on-premises and cloud. AWS Outposts is a seamless hybrid cloud solution that uses the same software, services, infrastructure, management tools, development and deployment models as organizations are already using on AWS. It supports workflows that are kept on-premises for low latency and local data processing needs, such as telecom virtual network functions, high-frequency trading, industrial automation, financial services, healthcare, and other applications.
The two AWS Outposts offerings are VMware Cloud on AWS service, which runs on AWS Outposts, and AWS Outposts, which allows customers to run compute and storage on-premises using the same native AWS APIs used in the AWS cloud.
Databases
Amazon had six announcements here covering blockchain, time series data, a global database, VMware and Dynamo DB.

Andy Jassy
People have wondered whether Amazon’s silence about blockchain meant the company didn’t consider it “a thing,” Jassy said. It turns out that Amazon has been working on blockchain as evidenced by its new Amazon QLDB managed ledger database and the new Amazon Managed Blockchain service. QLDB provides a transparent, immutable, and cryptographically verifiable transaction log owned by a central trusted authority. It tracks each application data change and maintains a complete and verifiable history of changes over time. It’s serverless, it autoscales and the revenue model is usage-based. The Amazon Managed Blockchain service makes it easy to create and manage scalable blockchain networks using Hyperledger Fabric (now) and Ethereum (soon).
Amazon Timestream is a serverless time series database service for collecting, storing, and processing time-series data including server and network logs, sensor data, and industrial telemetry data for IoT and operational applications. Jassy said it can process trillions of events per day at one-tenth the cost of relational databases, with up to 1,000 times faster query performance than a general-purpose database. Timestream automates rollups, retention, tiering and compression of data, so data can be managed at the lowest possible cost.
Amazon Aurora Global Database is a new feature in the MySQL-compatible edition of Amazon Aurora that allows a single Aurora database to span multiple AWS regions. It provides fast replication (with a typical latency of less than 1 second) for low-latency global reads and disaster recovery from region-wide outages. With a few mouse clicks, users can create an Aurora Global Database on the Amazon RDS Management Console or download the latest AWS SDK or Command Line Interface (CLI).
Amazon and VMware continue their partnership with the announcement of the new Amazon RDS on VMware service, which is now in preview. It delivers Amazon RDS managed relational databases in VMware vSphere on-premises data centers. Specifically, RDS on VMware automates database provisioning, operating system and database patching, backup, point-in-time restore, storage and compute scaling, instance health monitoring and failover.
RDS on VMware also enables low-cost, high-availability hybrid deployments, database disaster recovery to AWS and long-term database archival in Amazon Simple Storage Service (Amazon S3). It will soon expand to support more extensive data recovery, geoproximal read and migration functionality including hybrid RDS snapshots and hybrid read replicas (datacenter to/from datacenter and datacenter to/from AWS region), one-click read replica promotion and cross-cluster high availability.
Amazon DynamoDB on-demand is a new capacity mode for DynamoDB that instantly scales up or down to accommodate workloads. It offers simple pay-per-request pricing for read and write requests so users can balance costs and performance.
Machine Learning
Tens of thousands of AWS customers are using machine learning. Since there’s a shortage of experts, the AWS team has stratified its offerings to suit the experts who like to tinker, developers and data scientists and those who want to use machine learning but lack data science and development skills.
For example, Amazon SageMaker RL, Amazon’s new managed reinforcement learning service, enables developers and data scientists to quickly and easily develop reinforcement learning models at scale. While reinforcement learning does not require a lot of training data, it does require knowledge of the reward function of a desired outcome (and typically the path to getting there is unknown or would take a lot of iteration to discover). Use cases include gaming, healthcare treatments and manufacturing supply chain optimization.
Reinforcement learning is so complex and difficult to learn that it’s impractical for many organizations. Amazon SageMaker RL enables any developer to take advantage of it.
Speaking of machine learning, don’t forget about the importance of data. Amazon SageMaker Ground Truth helps users quickly build highly accurate training datasets. With it, developers can label their data using human annotators via Mechanical Turk, third party vendors, or their own company. Amazon SageMaker Ground Truth learns from the annotations in real time and can automatically apply labels to much of the remaining dataset, reducing the need for human review. It purportedly reduces costs by up to up to 70 percent when compared to human annotation alone.
Also, the AWS Marketplace now offers hundreds of machine learning algorithms and model packages that can be deployed directly on the Amazon SageMaker fully managed machine learning service. Free and paid algorithms and models are available for computer vision, natural language processing, speech recognition, text, data, voice, image, video analysis, predictive analysis and more.
To alleviate the pain and expensive of forecasting guesswork, enterprises can take advantage of Amazon Forecast which is a fully managed service that uses machine learning to produce highly accurate time-series forecasts. It uses historical data and related causal data to automatically train, tune and deploy custom, private machine learning forecasting models.
Frustrated with OCR text extraction? If so, you’re not alone because you’re getting extra text you don’t need and what you do need likely isn’t in a useful format. Amazon Textract, now in preview, automatically extracts text and data from scanned documents. Unlike OCR, it uses machine learning to identify the contents of fields in forms and information stored in tables and presents that information in the correct format without the need for manual data entry and review, extensive post-processing or custom code. Using Amazon Textract, developers can quickly automate document workflows, processing millions of document pages in a few hours.
Businesses that have been dying to get their hands-on Amazon’s recommendation engine for personalization now have access to Amazon Personalize, a machine learning service that enables developers to include individualized recommendations in their applications. Developers simply provide an activity stream from their application such as page views, signups or purchases and an inventory of the items they want to recommend to customers (e.g., articles, products, videos, or music.) Amazon Personalize processes and examines the data, identifies what’s meaningful, selects the right algorithms, and then trains and optimizes a personalization model that’s customized to the data provided.
Then there’s deep learning, which is one of the hottest areas of machine learning. However, deep learning inference costs can be prohibitively expensive. Amazon Elastic Inference purportedly slashes deep learning interference costs by 75% attaching the right amount of GPU-powered acceleration to any Amazon EC2 and Amazon SageMaker instance. Right now, it supports TensorFlow, Apache MXNet, and ONNX models. More frameworks will be available soon.
Speaking of inference, Amazon announced AWS Inferentia, a machine learning inference chip designed to deliver high throughput, low latency inference performance at an extremely low cost. The chip provides hundreds of Tera Operations Per Second (TOPS) of inference throughput to allow complex models to make fast predictions. For additional performance, multiple AWS Inferentia chips can be used in parallel to drive thousands of TOPS of inference throughput. The chip will support the TensorFlow, Apache MXNet, and PyTorch deep learning frameworks, as well as models that use the ONNX format.
Developers who want more scalable distributed training of TensorFlow deep learning models should check out the AWS Deep Learning Amazon Machine Interfaces (AMIs) for Ubuntu and Amazon Linux. They now support distributed training of TensorFlow deep learning models with near-linear scaling efficiency up to 256 GPUs. The AWS Deep Learning AMIs come pre-built with an enhanced version of TensorFlow that is integrated with an optimized version of the Horovod distributed training framework so the ResNet50 model can be trained with TensorFlow-Horovod in less than 15 minutes.
If you want to learn about machine learning (and specifically reinforcement learning) first-hand and want to have some fun doing it, check out AWS DeepRacer. There’s a fully autonomous 1/18th scale race car available for pre-order, as well as a 3D racing simulator and global racing leagues forming now. AWS DeepRacer learns complex behaviors without labeled training data, and it can make short-term decisions while optimizing for a longer-term goal.
Management/Compliance
Enterprises tend to have lots of AWS accounts that can result in expensive inefficiencies. AWS Control Tower automates the set-up of a secure baseline environment or landing zone that makes it easier to govern AWS workloads with rules for security, operations and compliance. With it, enterprises can allow teams to work independently while maintaining a consistent level of security and compliance.
Security, Identity and Compliance
Enterprises have lots of security solutions and they don’t necessarily have visibility across them. The new AWS Security Hub service, now in preview, provides a single place that aggregates, organizes, and prioritizes security alerts and findings from multiple AWS services, including Amazon GuardDuty, Amazon Inspector, Amazon Macie and AWS Partner solutions. Notably, it collects and prioritizes security findings across accounts, ingests data using a standard findings format and eliminates time-consuming data conversion efforts. In addition, it can run automated, continuous account-level configuration and compliance checks based on industry standards and best practices.
Storage
For compute-intensive High Performance Computing (HPC) or machine learning workloads, Amazon introduced Amazon FSx for Luster, which is a fully managed file system that can process file-based data sets from Amazon S3 or other durable data stores. With Amazon FSx for Lustre, users can launch and run a Lustre file system capable of processing massive data sets at up to hundreds of gigabytes per second (GB/s) throughput, millions of Input/Output Operations Per Second (IOPS) and sub-millisecond latencies. It’s seamlessly integrated with Amazon S3, so long-term data sets can be easily linked with high-performance file systems to run compute-intensive workloads. Users can automatically copy data from S3 to FSx for Lustre, run workloads, and then write results back to S3. FSx for Lustre also enables users to burst compute-intensive workloads from on-premises to AWS, by allowing access to an FSx file system over Amazon Direct Connect or VPN. It helps cost-optimize storage for compute-intensive workloads.
Based on customer demand, Amazon also introduced Amazon FSx for Windows File Server. It provides a fully managed native Microsoft Windows file system for easily moving Windows-based applications that require file storage to AWS. Since it’s built on Windows Server, Amazon FSx provides shared file storage with the compatibility and features that Windows-based applications rely on, including full support for the Server Message Block (SMB) protocol and Windows New Technology File System (NTFS), Active Directory (AD) integration, and Distributed File System (DFS). It uses Solid State Drive (SSD) storage to achieve fast performance and consistent sub-millisecond latencies. Amazon FSx was designed to eliminate the typical administrative overhead of managing Windows file servers. (Note: availability is currently limited to the US East (N. Virginia, Ohio), US West (Oregon) and Europe (Ireland) AWS regions.
Finally, there’s a new option for long-term data retention coming in 2019 which is S3 Glacier Deep Archive. It’s a new Amazon S3 storage class that provides secure, durable object storage for long-term data retention and digital preservation. S3 Glacier Deep Archive will be the lowest-priced storage option in AWS. It’s designed for customers who need to make archival, durable copies of data that rarely, if ever, need to be accessed. Specifically, it eliminates the need for on-premises tape libraries. Data can be retrieved within 12 hours.
About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now