

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
MapR adds Apache Spark to its Hadoop distribution to power machine learning plus ad hoc, graph, and streaming analysis. Databricks partners on support.
3 Min Read
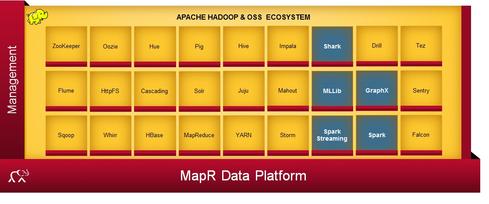
MapR is adding the Spark stack, highlighted in gray, to its list of more than 20 supported Apache open source projects.

20 Great Ideas To Steal In 2014
20 Great Ideas To Steal In 2014 (Click image for larger view and slideshow.)
MapR announced Thursday that it's bringing Apache Spark software and support to its Hadoop distributions. Software and support is available immediately through all of its Hadoop distributions through a partnership with Spark backer Databricks.
Spark is quickly establishing itself as a leading environment for doing fast, iterative in-memory and streaming analysis. The software can run stand-alone in a clustered environment, but it can also run on top of Hadoop by way of the YARN resource manager introduced last year in Hadoop 2.0.
The Spark software stack was created and turned over to open source by Databricks, a commercial company that certifies related software and offers installation and ongoing management support. The stack includes the core data-processing engine, an interface to Hive for interactive querying, Spark Streaming for streaming data analysis, and growing libraries for machine-learning and graph analysis.
[Want more on analytics on Hadoop? Read Pivotal Subscription Points To Real Value In Big Data.]
"People are really excited about using Spark because it's a way around traditional multi-step processing on Hadoop," said Anoop Dawar, senior director of product management at MapR. "Spark provides a fast way to do iterative machine-learning and model-learning because it caches results in memory for continuous analysis."

MapR adds the Spark stack, highlighted in gray, to its list of more than 20 supported Apache open source projects.
Spark also supports interactive, ad hoc exploration of data, using Hive, for example, and streaming analysis applications such as network threat detection and fraud risk analysis. In the streaming role it's used in combination with tools such as Kafka and Flume.
Cloudera became was the first Hadoop distributor to add Spark software and support with its Cloudera Enterprise release in February. MapR will ship Spark software with its M3, M5, and M7 software distributions and offers optional Spark support. MapR will handle first-level and second-level support for software installation and day-to-day management. When higher-level expertise is required, MapR can call in Databricks domain experts, but MapR maintains case management so "it's not a cold handoff," according to Dawar.
Our InformationWeek Elite 100 issue -- our 26th ranking of technology innovators -- shines a spotlight on businesses that are succeeding because of their digital strategies. We take a close at look at the top five companies in this year's ranking and the eight winners of our Business Innovation awards, and offer 20 great ideas that you can use in your company. We also provide a ranked list of our Elite 100 innovators. Read our InformationWeek Elite 100 issue today.
About the Author(s)
You May Also Like
More Insights
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now