

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
8 Reasons Big Data Projects Fail
Most companies remain on the big data sidelines too long, then fail. An iterative, start-small approach can help you avoid common pitfalls.
5 Min Read
Big data is all the rage, and many organizations are hell bent on putting their data to use. Despite the big data hype, however, 92% of organizations are still stuck in neutral, either planning to get started "some day" or avoiding big data projects altogether. For those that do kick off big data projects, most fail, and frequently for the same reasons.
It doesn't have to be this way.
[Want more big data advice on staffing? Read Data Scientists: Stop Searching, Start Grooming. ]
The key to big data success is to take an iterative approach that relies on existing employees to start small and learn by failing early and often.
Herd mentality
Big data is a big deal. According to Gartner, 64% of organizations surveyed in 2013 had already purchased or were planning to invest in big data systems, compared with 58% of those surveyed in 2012. More and more companies are diving into their data, trying to put it to use to minimize customer churn, analyze financial risk, and improve the customer experience.
Of that 64%, 30% have already invested in big data technology, 19% plan to invest within the next year, and another 15% plan to invest within two years. Less than 8% of Gartner's 720 respondents, however, have actually deployed big data technology.
That's bad, but the reason for the failure to launch is worse: Most companies simply don't know what they're doing when it comes to big data.

It's no wonder that so many companies are spending a small fortune to recruit and hire data scientists, with salaries currently averaging $123,000.
8 ways to fail
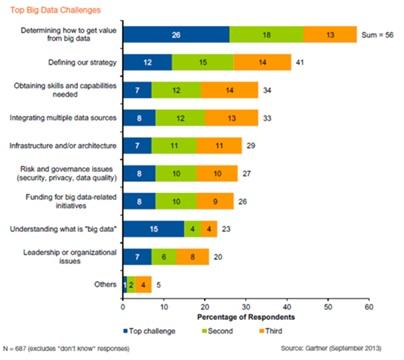
Because so many organizations are flying blind with their data, they stumble in predictable ways (including thinking that a data scientist will magically solve all their problems, but more on that below). Gartner's Svetlana Sicular has catalogued eight common causes of big data project failures, including:
Management resistance. Despite what data might tell us, Fortune Knowledge Group found that 62% of business leaders said they tend to trust their gut, and 61% said real-world insight tops hard analytics when making decisions.
Selecting the wrong uses. Companies either start with an overly ambitious project that they're not yet ready to tackle, or they attempt to solve big data problems using traditional data technologies. In either case, failure is the usual result.
Asking the wrong questions. Data science is a complex blend of domain knowledge (the deep understanding of banking, retail, or another industry); math and statistics expertise; and programming skills. Too many organizations hire data scientists who might be math and programming geniuses but who lack the most important component: domain knowledge. Sicular is right when she advises that it's best to look for data scientists from within, as "learning Hadoop is easier than learning the business."
Lacking the right skills. This one is closely related to "asking the wrong questions." Too many big data projects stall or fail due to the insufficient skills of those involved. Usually the people involved come from IT -- and those are not the people most qualified to ask the right questions of the data.
Unanticipated problems beyond big data technology. Analyzing data is just one component of a big data project. Being able to access and process the data is critical, but that can be thwarted by such things as network congestion, training of personnel, and more.
Disagreement on enterprise strategy. Big data projects succeed when they're not really isolated "projects" at all but rather core to how a company uses its data. The problem is exacerbated if different groups value cloud or other strategic priorities more highly than big data.
Big data silos. Big data vendors are fond of talking about "data lakes" and "data hubs," but the reality is that many businesses attempt to build the equivalent of data puddles, with sharp boundaries between the marketing data puddle, the manufacturing data puddle, and so on. Big data is more valuable to an organization if the walls between groups come down and their data flows together. Politics or policies often stymie this promise.
Problem avoidance. Sometimes we know or suspect the data will require us to take action that we don't really want to do, like the pharmaceutical industry not running sentiment analysis because it wants to avoid the subsequent legal obligation to report adverse side effects to the U.S. Food and Drug Administration.
Throughout this list, one common theme emerges: As much as we might want to focus on data, people keep getting in the way. As much as we might want to be ruled by data, people ultimately rule the big data process, including making the initial decisions as to which data to collect and keep, and which questions to ask of it.
Innovate by iterating
Because so many organizations seem hamstrung in their attempts to start a big data project, coupled with the likelihood that most big data projects will fail, it's imperative to take an iterative approach to big data. Rather than starting with a hefty payment to a consultant or vendor, organizations should look for ways to set their own employees free to experiment with data.
A "start small, fail fast" approach is made possible, in part, by the fact that nearly all significant big data technology is open source. What's more, many platforms are immediately and affordably accessible as cloud services, further lowering the bar to trial-and-error.
Big data is all about asking the right questions, which is why it's so important to rely on existing employees. But even with superior domain knowledge, organizations still will fail to collect the right data and they'll fail to ask pertinent questions at the start. Such failures should be expected and accepted.
The key is to use flexible, open-data infrastructure that allows an organization's employees to continually tweak their approach until their efforts bear real fruit. In this way, organizations can eliminate the fear and iterate toward effective use of big data.
When selecting servers to support analytics, consider data center capacity, storage, and computational intensity. Get the new Hadoop Hardware: One Size Doesn't Fit All issue of InformationWeek Tech Digest today (free registration required).
About the Author(s)
You May Also Like
More Insights
Webinars
How to Amplify DevOps with DevSecOps
May 22, 2024Generative AI: Use Cases and Risks in 2024
May 29, 2024Smart Service Management
June 4, 2024
Editor's Choice






May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now