

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Big Data Analytics: Time For New Tools
So you're considering Hadoop as a big data platform. You'll probably need some new analytics and business intelligence tools if you're going to wring fresh insights out of your data.
4 Min Read
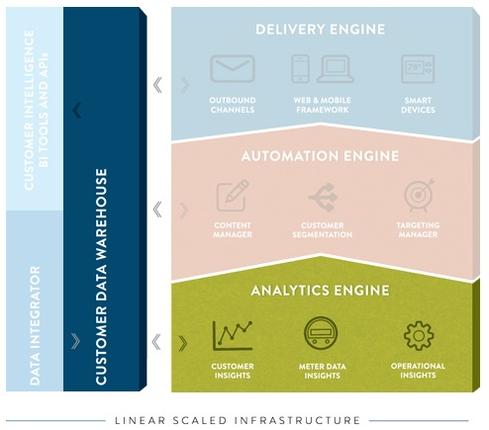
Opower's "Customer Data Warehouse" is Hadoop, which is used to store meter readings from more than 100 utilities, plus weather and real estate data.
reporting on something as simple as how many customers received a home-energy report, "I don't want that stored in too many different places, because you run the risk of having different calculations depending on where you pull that data from," Lomas explains.
Big data example No. 2: The schema-on-read advantage
Vivint is in the home-automation business, selling a system that lets customers monitor and control security, safety, heating, and air conditioning. The system includes a touchscreen control panel inside the house and mobile apps through which customers can remotely adjust heating or air conditioning, lock and unlock doors, and control lights or appliances. Sensor options include security cameras, thermostats, electronic door locks, door and window sensors, appliance-control switches, motion detectors, and smoke and CO alarms.
Vivint uses Hadoop to store the data from the more than 800,000 customers it serves. It chose Datameer and Platfora because "Hadoop isn't user friendly and lacks an intuitive interface," says Brandon Bunker, Vivint's senior director of customer intelligence and analytics. Without this software, "we would need data scientist and PhD types" to access and make sense of the data.
Many traditional BI tools have connectors to Hadoop, but they're best "when you know what questions you're going to ask in advance," Bunker says. "When businesspeople ask me new questions, I get same-day answers without having to create a new schema."
This schema-on-read capability provides one of the game-changing advantages of Hadoop. In a traditional database environment, you have to build a data model in advance, picking and choosing what data to include that you think might be relevant based on the questions that you suspect you will want to ask. Hadoop lets you store everything without having to fit it to a predefined data model.
Vivint has used this open-ended exploration of the data to help reduce false alarms, a problem that has dogged security companies for decades.
"You can imagine that there's a significant amount of data that can go into understanding when and why false alarms occur," Bunker says. With Hadoop, you can consider all the data, because you don't have to make assumptions about causes in advance.

The smart-home vendor Vivint collects heating, cooling, safety, and security sensor data in Hadoop. It uses big-data insight to cut down on false alarms.
Using Datameer to ingest, summarize, transform, join, and group data; Platfora for data visualization; and algorithms written in R and Matlab for prediction, Vivint can analyze all the data available in Hadoop, as opposed to limiting the scope of analysis by building a data model based on preconceived assumptions about the causes of false alarms.
"We're able to work with summary data as well as very granular data, so you can let the data do the talking, as opposed to relying on preconceived notions to solve that problem," Bunker says. Vivint considers its false-alarm analysis a trade secret and a source of competitive advantage.
Vivint has no shortage of tools at its disposal; it also uses Tableau Software and is experimenting with Spark (particularly its MLLib machine learning component). Tableau makes data visualization "easy for any user," Bunker says, but it slows down with larger data sets. When Vivint is analyzing truly big data, it relies on Datameer for its efficient data transformation, and Platfora to provide the equivalent of "an incredibly large OLAP cube in memory."
It's not a surprise that companies like Opower and Vivint, which do the bulk of their data work in Hadoop, are more inclined to use software that's part of or designed to work with that platform. Companies that use Hadoop on a limited basis and that have big investments in relational database management systems and conventional, SQL-oriented BI and analytics suites will naturally want to make the most of those tools.
But even if you're in the second camp, key takeaways here should be that not all big data questions can be easily answered with SQL, and not all tools developed for small data can cope with data variety or data at high scale. Keep these points in mind before you draw the wrong conclusions about early big data failures. It could be that your failures are due to using the wrong tools or starting with preconceived assumptions about what the data might tell you.
Apply now for the 2015 InformationWeek Elite 100, which recognizes the most innovative users of technology to advance a company's business goals. Winners will be recognized at the InformationWeek Conference, April 27-28, 2015, at the Mandalay Bay in Las Vegas. Application period ends Jan. 16, 2015.
About the Author(s)
You May Also Like
More Insights
Webinars
How to Amplify DevOps with DevSecOps
May 22, 2024Generative AI: Use Cases and Risks in 2024
May 29, 2024Smart Service Management
June 4, 2024
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now