

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Databricks Cloud: Next Step For Spark
Databricks, the company behind the hot Apache Spark project, announced new tools, new partners, and new funding to power a cloud service on Amazon Web Services.
3 Min Read
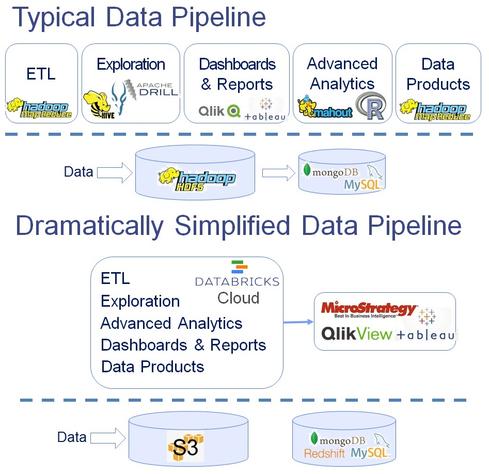
Databricks' depiction of Databricks Cloud replacing the many components of Hadoop used in today's big-data analyses.

Hadoop Jobs: 9 Ways To Get Hired
Hadoop Jobs: 9 Ways To Get Hired (Click image for larger view and slideshow.)
Apache Spark is already one of the most active open source projects in the big data world, but announcements made on Monday by Spark promoter and support firm Databricks could really heat things up.
The announcements, made at the sold-out Spark Summit 2014 in San Francisco, include the launch of the Databricks Cloud service on Amazon Web Services, set for general availability this fall, and the close of $33 million in new venture capital funding. This news comes on the heels of fresh partnership announcements with Hadoop distributor Hortonworks and Cassandra NoSQL database developer DataStax. And Databricks had already struck up partnerships with all other Hadoop distributors, including Cloudera, MapR, IBM, and Pivotal.
[Want more on Databricks' plans? Read Will Spark, Google Dataflow Steal Hadoop's Thunder?]
Spark is already deployable on AWS, but Databricks Cloud is a managed service based on Spark that will be supported directly by Databricks. Spark is best known for in-memory machine learning, but it also supports streaming analysis and SQL analysis, and work is underway on adding support for the popular R analytics library and graph analysis. All of these capabilities are exposed through a new Databricks Workplace component of Databricks Cloud, with Notebook, Dashboard, and Job-Launcher apps that the vendor said make it easy to build data-analysis pipelines from storage and ETL, to dashboarding and reporting, and on to advanced analytics and collaboration.
Databricks is not presenting Spark or Databricks Cloud as a replacement for Hadoop -- the platform needs to run on top of a data platform such as Hadoop, Cassandra, or S3. But it is saying that Spark can replace many of the familiar data-analysis components that run on top of Hadoop, including MapReduce, Pig, Hive, Impala, Drill, and more.
{image 1}
"We believe that the vast majority of jobs that organizations do in existing data pipelines can be done on top of Spark," said Ion Stoica, Databricks CEO, in a phone interview with InformationWeek.
Databricks depicts a "Typical Data Pipeline" being replaced outright by Databricks Cloud, with ODBC connections making it possible to use conventional BI tools including MicroStrategy, QlikView, or Tableau Software (see images).
For now, Databricks Cloud runs exclusively on AWS S3, but Stoica said the company will also explore options to run on other clouds, including Google Compute Cloud and Microsoft Azure. If customers want or need to deploy on premises, Hadoop and Cassandra are both options to provide the basics of a data platform, including storage, high availability, redundancy, and so on. But with this week's announcements, Databricks is stepping up and saying that Spark can handle the vast majority of high-value analytical work, whether that's MapReduce, machine learning, graph processing, streaming analysis or R-based data mining, or the SQL role that Hadoop vendors have been squabbling about over the last year or more.
Can Spark really supplant such an array or data-analysis tools? That's the subject of our analysis, "Will Spark, Google Dataflow Steal Hadoop's Thunder?," which includes reactions from Hadoop vendors. Our first take is that Spark has a lot to prove in real-world production deployments before it can reshape big data analysis as we know it.
With Monday's announcement, Databricks Cloud enters limited beta release. Stoica says it will be ready on Amazon by this fall, starting at "a couple of hundred dollars" per user, per month.
InformationWeek's new Must Reads is a compendium of our best recent coverage of the Internet of Things. Find out the way in which an aging workforce will drive progress on the Internet of Things, why the IoT isn't as scary as some folks seem to think, how connected machines will change the supply chain, and more. (Free registration required.)
About the Author(s)
You May Also Like
More Insights
Webinars
Editor's Choice





May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now