

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
The Architecture of Enterprise Data Quality
A finger in the dam won't stop the flood of operational data coming your way, but in-database mining will help you adapt to the flow.
9 Min Read

The intent of business intelligence (BI) is to help decision makers make well-informed choices. Therefore, modern BI systems must be able to consume vast quantities of detailed, disparate data and quickly reduce it to meaningful, accurate information that people can then confidently act on. The corollary of data quality is better decision-making.
An immediate challenge for data architects, however, is the ever-rising flood of operational data that must be cleansed, integrated, and transformed. These tasks must address enterprise-scale issues, including the ever-increasing volume and variety of data and, in some cases, near real-time data refresh levels.
Up to the Job?
Most traditional data quality tools, whether they're implemented as stand-alone solutions or used to supplement extract, transform, and load (ETL) processing, are inadequate for enterprise-scale implementations. Most of them simply can't scale to enterprise-level data volumes and refresh frequencies (from batch to continuous).
To illustrate, let's consider the data flow dictated by the cleansing and transformation batch processing that's common to these tools. First, the data must be extracted from the source and temporarily stored in files or tables for processing. The data is then cleansed, transformed, or otherwise prepared according to predefined data quality rules. During this process, the data is moved in and out of temporary files or tables as required. When the data is prepared to the defined specifications, it's temporarily stored again. Finally, the data is moved from the final temporary storage and loaded into the target data warehouse tables or passed on to the ETL technology for further processing. When you consider all the batch data movement required by typical data quality software, it's easy to see that the technology can quickly become a process bottleneck as data volumes or refresh rates increase.
The enterprise-scale requirements of data quality, coupled with the limitation of traditional data quality technologies, leave architects with few options. Some architects have merely lowered expectations. They either implement data quality processes for only critical data or constrain quality processing to pedestrian activities, such as simple standardization. And although these approaches may serve as workarounds to handle data volume issues, they operate at the expense of the trustworthiness of the overall warehouse. Poor-quality data compromises virtually all the analytics and, therefore, the data warehouse's value to decision makers.
First Things First
But the seasoned architect is aware that certain techniques and technologies can be adapted to meet the requirements of enterprise data quality, specifically, in-database data mining now offered by leading database vendors. But before I can continue with how to incorporate in-database mining into your data quality solution, it is critical that you:
Look beyond the typical applications associated with data mining technology. Data mining is too quickly pigeonholed as an esoteric application used only for prediction or forecasting.
Appreciate the value in-database data mining brings to the modern warehouse.
First, to understand what data mining can do for data quality, you must understand the level of data quality needed for data mining applications. Approximately 70 percent of data mining activity is focused on data preparation. That's an astounding amount of time spent exploring, cleaning, and transforming target data. But it's a necessary investment if the data mining application is going to work properly. Data mining must have good, clean data. Consequently, data mining technology includes functions that assist in achieving the high level of quality necessary. These functions efficiently profile, audit, scrub, and otherwise transform raw data into quality data sets that can then be used for analytic purposes. These data quality functions and techniques have matured over the decades in data mining applications that we want to exploit in our own data warehouse activities.
Second, the sophistication of data quality functions for data mining not only address a full range of data profiling and cleansing, they do so with an innate ability to efficiently run against large volumes of detail data.
Still, one of the challenges for using data mining technology has always been that of getting data into the mining environment. In the case of in-database mining, however, we can actually bring mining to the data. For instance, all Teradata Warehouse Miner data mining models and functions are translated into Teradata SQL and executed directly in the Teradata Warehouse, against the entire database. Therefore, in-database data mining technology exploits all the power and scalability of the entire database environment, making it a perfect environment to handle data quality processing.
The Architecture of Enterprise Data Quality
BI represents a broad spectrum of analytic applications, from traditional data warehouse to business activity monitoring. From one application to another, the source data, the frequency of sourcing, and the data detail and volume may differ. A fragmented data quality process — that is, cobbled together — simply won't work, especially in enterprise-scale implementations.
A formal data quality strategy and architecture must be developed, not unlike the customary data architecture and technical architecture found in BI implementations. This architecture must focus on providing a seamless integration of data quality metrics between multiple architectural touchpoints that share the workload. This rigor ensures scalability, in terms of data volumes, frequency of data stream (batch or continuous), and complexity of processing.
There are several layers to the architecture shown in Figure 1. At the bottom is the overall Enterprise Data Quality Services layer: Its objectives are to monitor, collect, synthesize, and distribute data quality metrics across the architecture. This layer's importance can't be overstated. The key component to any enterprisewide data quality initiative is the ability to accurately capture data quality metrics and immediately make them available to the network of data quality processes. For example, if you determine that the valid range for new invoice numbers is now between 100,000 and 500,000, then that metric must be shared with those data quality touchpoints that depend on the information. One such touchpoint is the intratable cleansing process of incoming source data and the intertable transformations for integrating related data (such as relating a valid invoice number to a customer payment).
The next layers of the architecture start with the Enterprise Data Quality Business Rules Engine. This layer represents a coordinated system of processes that applies specific business rules across all architecture touchpoints and, subsequently, to the actual data quality functions invoked.
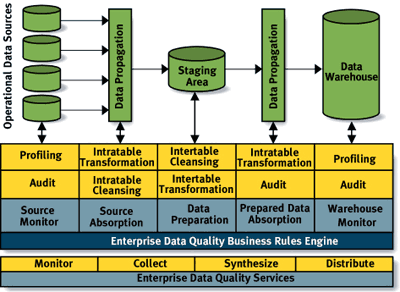
FIGURE 1 An enterprise data quality architecture.
Above the Enterprise Data Quality Business Rules Engine are the touchpoints between the data quality process and the physical data. The number and type of touchpoints will vary depending on the environment. The reach and control afforded the data quality initiative may allow touchpoints to be established at the point of origin for source data, or your environment might include other data structures, such as an operational data store. Nevertheless, the following touchpoints are common to most enterprise environments:
Source monitor. A touchpoint to monitor the target sources of data destined for the BI environment. Two data quality functions are defined for this touchpoint: continuously auditing the source data and detailed data profiling. The resulting findings are fed back to the Data Quality Business Rules Engine as metrics to be used to tune subsequent data quality functions.
Source absorption. This touchpoint focuses on incoming source data. It applies known business rules taken from the rules engine to resolve cleansing and transformation processes. The processes applied here are intratable only.
Data preparation. A staging area is reserved for the majority of incoming source data. This area is commonly used for the majority of cleansing and transformation functions, including such activities as data integration and subsequent intertable quality checks and assignment of primary keys.
Prepared data absorption. This touchpoint is related to data propagation between the staging area and the target data warehouse. At least two quality functions apply to this touchpoint: intratable transformation and data audit. Further transformation, such as aggregation, is often required before loading data into the warehouse. Of course, this task can also be done at the data preparation touchpoint. But it's important to demonstrate that architects have flexibility to spread out data quality processes.
Warehouse monitor. It may sound unusual for your data quality strategy to include monitoring the warehouse — the final destination of supposedly cleansed data. But in fact, data quality problems plague the data warehouse. Even data that was clean when initially loaded may erode over time; for instance, if a customer dies, divorces, or marries. Consequently, the warehouse must always be monitored to ensure that data, once stored, is still valid and meaningful for analytics.
This architecture overcomes the scalability problem that haunts traditional data quality solutions, whether they're stand-alone products or part of an ETL suite. It distributes the workload of data quality processing across applicable touchpoints, thereby eliminating the situation where much of your data quality processing is done as a single batch event at a particular touchpoint.
The challenge with distributing data quality tasks across your environment has always been twofold: the need to share metadata among data quality touchpoints and establish an overall quality rules engine to ensure the latest metrics are being applied. This architecture overcomes both of these challenges by establishing a cohesive network of data quality processing that shares metrics and takes direction from a centralized rules engine, all implemented with the data warehouse itself.
Delivering on the Promise
The speed with which you can cleanse, transform, and absorb data into warehouse structures and BI applications is critical to the success of many organizations. With global companies operating 2437, there's literally no time available for traditional data warehousing technologies. It's here where virtually all traditional approaches to data warehousing are made obsolete, including data quality.
With in-database data mining technology, however, solution strategists and architects can design and implement comprehensive, adaptive data quality solutions. These solutions can complement existing ETL processes just like traditional data quality technology, or be the foundation to a pure in-database platform solution that performs cleansing and transformation. In either case, proper implementation of this in-database capability ensures the necessary data for analytics and delivers on the promise of business intelligence.
Michael L. Gonzales is the president of The Focus Group Ltd., a consulting firm specializing in data warehousing. He has written several books, including IBM Data Warehousing (Wiley, 2003). He speaks frequently at industry user conferences and conducts data warehouse courses internationally.
Acknowledgments
The contents of this article were taken with permission from a white paper ("Enterprise Data Quality for Business Intelligence," Oct. 2003) written by Michael L. Gonzales and published by Teradata. You can download it at http://www.teradata.com/t/go.aspx/?id=42137.
Players in the Field |
|---|
All leading database vendors provide in-database mining technology. IBM offers several products that support seamless integration between data mining and the DB2 relational database, including DB2 Intelligent Miner for Data, DB2 Intelligent Miner for Scoring, DB2 Intelligent Miner Modeling, and DB2 Intelligent Miner Visualization. Oracle offers Oracle Data Mining as an option to the Oracle 10g Enterprise Edition that affords a full line of data mining models and related analysis. It also offers Oracle Data Mining for Java (DM4J), providing components as JDeveloper extensions. Even Microsoft provides two mining models with its current version of SQL Server that can mine Microsoft cubes or relational data. |
About the Author
You May Also Like
More Insights




