

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Cascading Backer Boosts Hadoop App Performance Management
Concurrent, the firm behind Cascading app development, adds Hive and MapReduce support to its Driven performance-management system.
4 Min Read
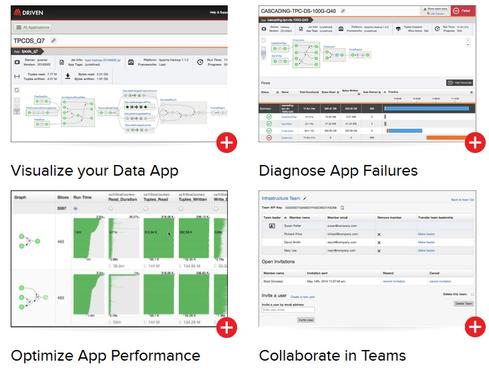
Concurrent backs the open source Cascading big data application development platform. Driven, pictured above, is its commercial app performance-management system.

10 Big Data Online Courses
10 Big Data Online Courses (Click image for larger view and slideshow.)
With Hadoop quickly emerging as an applications platform as well as a big data-processing environment, Concurrent is broadening its Driven application performance-management system to monitor and manage a variety of data-centric applications.
Concurrent is the commercial vendor behind open source Cascading, arguably the most popular big data application-development option going -- after native coding on separate platforms. Driven is Concurrent's commercial product, but it's not a souped-up version of Cascading. Rather, Driven is a separate big data application performance-monitoring and management system.
Where Hadoop vendors and analytics platforms like Apache Spark have their own management consoles that look at the health and performance of their clusters, Driven monitors and helps troubleshoot the performance of data-driven applications across multiple platforms and environments. That could be various Hadoop distributions or emerging systems like Spark, Storm, Tez, or other analytic platforms.
"Those other management consoles focus on the data fabrics where Driven focuses on the applications," said Chris Wensel, founder and CTO of Concurrent, in a phone interview with InformationWeek. "We bring visibility to the version, the developer, and the process owner, and we help you understand what the application does, what libraries it depends upon, and most importantly, how it interacts with upstream and downstream applications."
[Want more on Cascading? Read Hortonworks Adds Cascading For Big Data App Development.]
Where other management systems might help with post-mortem analysis, Wensel said Driven lets developers, operations, and line-of-business staff visualize myriad apps running on clusters and measure growth in demand, by app and by business unit, over time. And when applications fail, Driven is designed to surface how that will impact other applications so specific jobs can be killed or rerun and users or customers can be notified if there will be disruptions.
The first release of Driven, which came out in June, supported monitoring and management of Cascading, Scalding, and Cascalog applications, but with this week's 1.1 update, Concurrent is adding support for Hive and bespoke MapReduce applications. Despite the emergence of multiple SQL-on-Hadoop options and MapReduce alternatives, these two options are still doing the bulk of the heavy lifting in Hadoop environments.
"Everybody wants to get to the next thing that will be faster than MapReduce, but they probably won't go there for another two years because MapReduce works, they understand it, and they know the operational risks," said Gary Nakamura, Concurrent's CEO.
The combination of Cascading and Driven will let big data practitioners keep applications running and well managed, yet requirements for change to those apps will be minimal if they end up switching from MapReduce to alternatives like Spark or Tez, Nakamura said.
Other upgrades in Driven 1.1 include deeper visualizations for monitoring, managing, and debugging applications; search capabilities designed to quickly spot problematic applications; timeline visualizations to track app utilization trends; and app-segmentation support by tags, names, teams, or organizations so teams can track service-level agreement compliance and Hadoop utilization for internal or external chargebacks.
Driven has been generally available for only four months, so Wensel said it's no surprise there are fewer than a dozen customers at this point. The only publicly identified Driven customer is the Dutch email advertising optimization vendor Mojn.
"With Driven, our developers have unmatched operational visibility and control across all Cascading applications -- including real-time monitoring, history and performance tracking over time," said Johannes Alkjær, lead architect at Mojn, in a statement from Concurrent. "Driven [lets us] drive differentiation through our data and manage our data applications more efficiently."
Concurrent is counting on the popularity of Cascading to drive interest in Driven. There are more than of 8,000 production deployments of Cascading (including uses at Twitter, United Healthcare, Etsy, and Nokia), and the software is getting more than 285, 000 downloads per month, according to Concurrent.
Cascading owes its popularity to the fact that it abstracts developers from the complexities of Hadoop programming so they can write once and deploy across multiple distributions and generations of distributions. Concurrent does the work making sure its platform stays up to date and compatible with multiple big data platforms as they evolve.
Cascading has been certified to work on multiple distributions and works with the YARN resource management framework. Concurrent also offers beta Cascading software and is preparing future production releases that will support for Spark, Storm, and Tez as they become generally available.
What will you use for your big data platform? A high-scale relational database? NoSQL database? Hadoop? Event-processing technology? One size doesn't fit all. Here's how to decide. Get the new Pick Your Platform For Big Data issue of InformationWeek Tech Digest today. (Free registration required.)
About the Author(s)
You May Also Like
More Insights
Webinars
How to Amplify DevOps with DevSecOps
May 22, 2024Generative AI: Use Cases and Risks in 2024
May 29, 2024Smart Service Management
June 4, 2024
Editor's Choice






May 2, 2024
While there are plentiful options in cyber resiliency and business continuity tools and platforms, there isn’t one that can knock out everything from sudden cloud outages to prolonged ransomware attacks in a single punch. What can you do to keep the company on its feet no matter what is thrown at it? Find out in this new virtual event.
Reserve Your Seat Now