

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
End the Conflict: Resolve Customer Data Inconsistency
The conflict must end: To provide strategically important customer sales, marketing, and service, your organization must get past the turf battles and establish solid, timely, and high-quality customer data.
11 Min Read

If your company is one of the many that have collectively invested billions of dollars in customer relationship management systems, you know that it's still difficult for a large enterprise with CRM to get a consistent view of any given customer across the entire enterprise. Without an accurate picture of your customers, however, you are losing opportunities to pursue additional revenue and increase customer profitability.
Customer data in large enterprises is usually located in multiple applications: Front-office systems such as sales force automation systems, order management, and call center management systems; back-office systems such as ERP; and homegrown operational and shipping systems. Therefore, some of the customer data ends up duplicated in multiple applications.
Each application has a proprietary data model, and therefore may represent the same customer in different ways — with dissimilar customer codes and diverse attributes. For example, the ZIP code in one application may be represented in a 5+4 numeric data format; while in another application it may be represented in 9 characters to accommodate foreign postal codes.
To address such diversity, IT organizations write large amounts of manual code to integrate the data from multiple apps, including semantics rules and validation techniques, to ensure that duplicated customer data and dissimilar customer attributes remain consistent across these applications. For example, there may be semantics rules to ensure that before the customer reference records are updated in the target application, the birth date of a customer is never later than the death date or the customer address is in the right format. Many of these rules are deeply embedded inside applications.
However, as applications are upgraded or new applications are added into the ecosystem, these embedded rules sometimes miss being upgraded or fail to trigger. As a result, changes to customer data in one application either do not propagate or propagate erratically to other applications. Consequently, critical information about the customer, duplicated across these IT systems, begins to fall out of sync over time and becomes inconsistent and inaccurate. The unfortunate outcome is that the business loses opportunities to pursue new revenue and increase profitability when plans are based on inconsistent data or lack of a common view of the customers.
Some companies have tried to resolve this inconsistency by treating a certain application as the source of truth for certain types of customer data. For example, a mobile phone company may create a business rule designating the call center application as the source of truth for the customer home phone number.
However, these rules are difficult to deploy in a world where customers have multiple channels of interaction with the company. For instance, if a customer walks into the mobile phone company's retail outlet to sign up for a promotional offer and happens to provide her new home telephone number, the business rule I just mentioned will prevent the propagation of the correct phone number to the company's other applications.
Other companies have attacked the problem by standardizing on a single business application across the entire enterprise. However, this approach is not very practical: Most business applications make it difficult to model every customer-related process across all product lines within a large company.
Two new approaches are emerging that solve the problem of customer data inconsistency across applications. I'll now describe them and their successes to date.
One Approach: Centralized Semantics Store
The first approach, that of the centralized semantics store, comes from this assumption: If the data rules that are applied during application integration always keep pace with any upgrades or changes to the applications, then the customer data across those applications will always stay consistent. Therefore, the centralized semantics store technique focuses on centralizing all the rules (validation, transformation, aggregation, and business rules) in one common repository and making them available to various applications. As applications are upgraded, the centralization of these rules makes it easier for IT organizations to ensure that these rules are constantly updated to support the changes to the applications environment. As a result, the customer data within the enterprise can be kept consistent and accurate across various applications.
Two Commercial Examples
Pantero, a recent startup, provides a very innovative solution using this approach. Its solution has taken a model-driven approach to centralizing all the rules associated with ensuring semantics consistency across applications. Pantero's SDS suite (as in "shared data services") first allows the software analyst to define a domain model — a physical representation of the data being shared among the related applications. Domain models are often derivatives of existing canonical models used for interchange and integration, such as ACORD for insurance, MISMO for mortgages, and RosettaNet for high technology.
That model is then used as a context to define all the rules for transformation, aggregation, validation, and business policies for any data exchanged between the applications. (See Figure 1.) As a result, all the rules associated with data interoperability are externalized, modeled, and managed in one repository, rather than being hard-coded within the integration layer and within several applications.
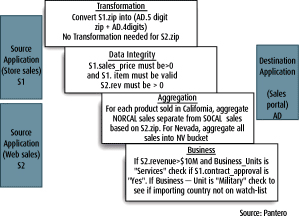
Figure 1 Examples of semantics rules that are deeply embedded within applications.
Pantero SDS suite then enables the software developer to combine the relevant rules into a set and make them accessible, using a Web service, to any application. Therefore, when an application invokes a Pantero Web service, such as update-customer-profile, Pantero applies the selected set of semantics rules to the incoming data and then makes the processed data available to the application.
Therefore, the application or the integration layer does not need to write any manual code that is later at risk of not being upgraded over time. In addition, centralization of these rules allows other applications to easily reuse these rules, reduce redundancy, and further reduce the risk of inconsistent data in the future. When one of the applications is upgraded, Pantero's change-management capabilities identify the rules that need to be changed. Because only the identified rules in the centralized rules repository need to be modified to ensure continued application interoperability, the cost of maintaining application integration is also dramatically reduced.
Many services-oriented vendors are also using this paradigm to create off-the-shelf adapters to connect packaged applications. For example, Sierra Atlantic, a systems integration company, has developed off-the-shelf adapters for major applications such as Siebel, Clarify, Oracle, and PeopleSoft to ensure that data across these applications is always consistent and accurate in any deployment. Sierra Atlantic's applications network products incorporate all the rules that transform, validate, aggregate, and synchronize customer-related data between selected packaged applications. Many Fortune 1,000 companies have taken a best-of-breed approach to selecting and deploying packaged applications and are using such off-the-shelf adapters to ensure continued interoperability and consistency of customer data across various packaged applications.
Another Approach: Master Reference Store
Technologists who implement the second approach, using a master reference store, maintain the core belief that the problem of inconsistent and inaccurate customer data within an enterprise can be solved better by consolidating critical information about the customer in one location. This consolidated master reference store is then used as the source of truth within all applications in the enterprise.
By centralizing customer reference data, IT organizations can restore trustworthiness to customer reference data within all applications.
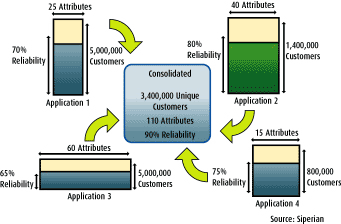
Figure 2 Consolidation of customer reference data in a single repository.
In any operational system, there are three distinct types of data: reference, transactional, and derived. Though these data types have very different characteristics, they have traditionally been treated by most systems in the same way.
Reference data usually comprises attributes that describe the customer, such as name, address, and phone number. This data about the customer changes on an ongoing basis.
Transactional data represents the historical facts about the customer, such as last 10 purchases, and typically does not change. This data is captured by systems as a result of business transactions.
Derived data is a set of facts generated from other data, using a mathematical operation or a data transformation. These figures can be aggregated across all customers or groups of customers to generate reports summarizing the overall health of the business.
Because a Fraction of the Data Is the Most Complex
Reference data is only a fraction of the customer-related data within the enterprise, but it represents most of the complexity associated with managing and maintaining information reliability. Why? The reference data, which is duplicated across enterprise applications, can quickly get out of sync and become inconsistent and inaccurate.
Without accurate customer reference data, it's impossible to accurately aggregate transactional data and calculate derived data. Therefore, this approach starts with an assumption that in order to eliminate inconsistency and improve accuracy of the reference data, enterprises need to consolidate the customer reference data from multiple applications into a single location.
Once this reference data is consolidated, it becomes the source of truth for all customer reference data within the enterprise. All applications can then synchronize their own customer reference data to this source of truth. Anytime a transaction in any application triggers a change to the customer reference data (such as when a customer contacts a call center to inquire about the latest credit-card activity and subsequently provides his or her new mobile phone number), this change is quickly propagated into the consolidated customer reference. This action in turn triggers an event that asks all other applications to update that information within their respective databases. As a result, each application is no longer directly responsible for updating every other application that is affected by a change in reference data. It therefore becomes simple and feasible to keep customer reference data in sync within all applications.
Siperian is one of the early pioneers in this solution category and is currently deployed at several companies in the high technology, financial services, and pharmaceutical industries.
Documentum Case Study
One of Siperian's early customers is Documentum, a fast-growing division of EMC. Documentum needed to keep the customer information within its marketing automation system (MAS) and sales force automation (SFA) system in sync, to enable the marketing organization to identify new leads from a new campaign as quickly and accurately as possible.
The two applications had different data models, and the integration layer had to map one set of fields to another application's format. In addition, the integration solution layer needed to handle duplicate, incomplete, or incorrect information. Incomplete or inconsistent data entered the system when prospects filled out online forms during marketing campaigns. Unfortunately, the two systems had incompatible mechanisms to programmatically update reference data changes, making it impossible to automatically keep the two systems in sync.
Because the company had no convenient way to automatically synchronize customer reference data between its sales and marketing systems, the staff identified new leads by manually comparing the customer and prospect information in the two systems and then cleaning the new lead data and loading it into the SFA system — a process that often took days, depending on the number of records. The sales team often had to wait until long after a marketing event to gain access to the new leads. Migrating to a single CRM system was not a cost-effective solution for the company.
Documentum selected Siperian to solve the problem. Using Siperian, Documentum was able to easily synchronize customer data between its SFA system and MAS, and gained an ability to create a composite view of the customer that was accurate and consistent between the two systems.
Several leading enterprise application providers such as SAP and Siebel have also developed products using the same approach to address the customer data integration needs of their customers. SAP's Master Data Management (MDM) application enables its customers to store, change, and consolidate master data in a centralized repository, while ensuring its consistent distribution to other systems. Siebel's Universal Customer Master (UCM) application unifies customer data across multiple business units and functionally disparate systems, providing a single authoritative source of customer information across the enterprise. MDM and UCM solutions are most relevant to companies that have selected SAP or Siebel as their standard to manage the majority of their customer-facing processes.
Which Way Should You Go?
The two approaches I have described use very different tactics to solve the customer data integration problem. The centralized semantics store approach posits that customer data should stay federated within its respective applications and only the rules need be centralized to ensure that the data always stays current. The master reference store approach, in contrast, centralizes key customer data in a common repository. However, both approaches have demonstrated early success in the marketplace.
The best solution for your company may depend on the volume of customer data, how frequently your data changes, and the nature of the portfolio of applications you need to integrate. With either approach, though, the problem of inconsistent customer data across applications can be resolved, helping you more effectively leverage customer data to identify revenue and profit enhancement opportunities.
Anil Gupta [[email protected]] is a principal at The Applications Marketing Group and a research advisor to Ventana Research on customer intelligence and demand chain performance. He advises his clients on strategic marketing issues including product positioning, market segmentation, and go-to-market strategy.
Resources
Pantero: www.pantero.com
SAP: www.sap.com
Siebel: www.siebel.com
Sierra Atlantic: www.sierraatlantic.com
Siperian: www.siperian.com
About the Author
You May Also Like
More Insights




