

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Get Started With Data Mining Now
Are you missing valuable data mining opportunities?
10 Min Read

 Data mining has come into its own over the past decade, taking a central role in many businesses. We're all the subject of data mining dozens of times a day—from the direct mail we receive to the fraud-detection algorithms that scrutinize our every credit card purchase.
Data mining has come into its own over the past decade, taking a central role in many businesses. We're all the subject of data mining dozens of times a day—from the direct mail we receive to the fraud-detection algorithms that scrutinize our every credit card purchase.
Data mining is widespread because it works. The techniques can significantly improve an organization's ability to reach its goals. Its popularity is also rising because the tools are better, more broadly available, cheaper and easier to use.
Many data warehouse/business intelligence (DW/BI) teams aren't sure how to get started with data mining. This column presents a business-based approach that will help you successfully add data mining to your DW/BI system.
The data mining process must begin with an understanding of business opportunities. The diagram on the right shows the three phases of the data mining process, major task areas within those phases and common iteration points.
The Business Phase
This first phase is a more focused version of the overall BI/DW requirements gathering process. Identify and prioritize a list of opportunities that can have a significant business impact. The business opportunities and data understanding tasks in the diagram connect because identifying opportunities must be connected to the realities of the data world. By the same token, the data itself may suggest business opportunities.
As always, the most important step in successful BI isn't about technology, it's about understanding the business. Meet with businesspeople about potential opportunities and the associated relationships and behaviors captured in the data. The goal of these meetings is to identify several high-value opportunities and carefully examine each one. First, describe business objectives in measurable ways. "Increase sales" is too broad—"reduce the monthly churn rate" is more manageable. Next, think about what factors influence the objective. What might indicate that someone is likely to churn? How can you tell if someone would be interested in a given product? While you're discussing these factors, try to translate them into specific attributes and behaviors that are known to exist in a usable, accessible form.
After several meetings with different groups to identify and prioritize a range of opportunities, take the top-priority business opportunity and its associated list of potential variables back to the DW for further exploration. Spend a lot of time exploring the data sets that might be relevant to the business opportunities discussed. At this stage, the goal is to verify that the data needed to support the business opportunity is available and clean enough to be usable.
You can discover many of the content, relationship and quality problems firsthand through data profiling—using query and reporting tools to get a sense of the content under investigation. While data profiling can be as simple as writing some SQL SELECT statements with COUNTs and DISTINCTs, several data profiling tools can provide complex analysis that goes well beyond simple queries.
Once you have a clear, viable opportunity identified, document the following:
Business opportunity description
Expected data issues
Modeling process description
Implementation plan
Maintenance plan.
Finally, review the opportunity and documentation with businesspeople to make sure you understand their needs and they understand how you intend to meet them.
The Data Mining Phase
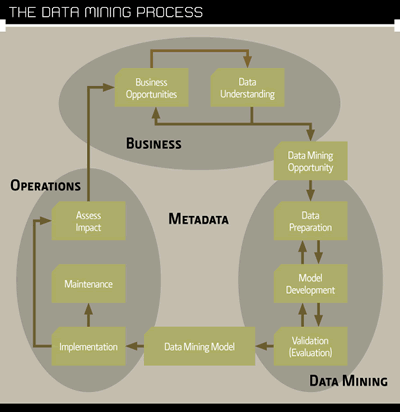 Now you get to build some data mining models. The three major tasks in this phase involve preparing the data, developing alternative models and comparing their accuracy, and validating the final model. As shown in the diagram at right, this is a highly iterative process.
Now you get to build some data mining models. The three major tasks in this phase involve preparing the data, developing alternative models and comparing their accuracy, and validating the final model. As shown in the diagram at right, this is a highly iterative process.
The first task in this phase is to build the data mining case sets. A case set includes one row per instance or event. For many data mining models, this means a data set with one row per customer. Models based on simple customer attributes, such as gender and marital status, work at the one-row-per-customer level. Models that include repeated behaviors, such as purchases, include data at the one-row-per-event level.
A well-designed and built dimensional DW is a perfect source for data mining case data. Ideally, many variables identified in the business opportunity already exist as cleansed DW attributes—often true with fields such as customer_type or product_color. The data miner's world gets even better when demographics and other external data are already loaded into the DW using conformed dimensions.
While descriptive data is important, the most influential variables in a data mining model are typically behavior-based. Behaviors are generally captured in the DW as facts detailing what customers did, how often, how much and when.
(Warning: Accurately tracking history using the Type 2 slowly changing dimension technique is critical to successful data mining. If your DW or external sources overwrite changes in a Type 1 fashion, your model will be associating current attribute values with historical behavior.)
The process of building the case sets usually involves queries and transformations that generate a data structure made up of individual observations, or cases, often with repeating nested structures that will be fed into the data mining service. The process is typically similar to the conventional extract, transform and load (ETL) process used to build the DW itself. Writing the data mining case sets to a separate database (or machine) lets you manage these tables independently from the DW.
ETL tools are well suited to creating case sets because you can encapsulate all the selection and cleansing components in a single ETL job. You can also leverage many of the transformations in the process.
 Depending on the business opportunity and data mining algorithms used, developing the initial data sets often involves creating separate data subsets for different purposes. The table above lists three common sets used for data mining. Your ETL tool should have simple transformations that let you grab a random sample of 10,000 rows from a large data set and then send 80% of the those rows to a training set and 20% to a test set.
Depending on the business opportunity and data mining algorithms used, developing the initial data sets often involves creating separate data subsets for different purposes. The table above lists three common sets used for data mining. Your ETL tool should have simple transformations that let you grab a random sample of 10,000 rows from a large data set and then send 80% of the those rows to a training set and 20% to a test set.
After developing the data sets, start to build some data mining models. Build as many different mining models and versions as time allows; try different algorithms, parameters and variables to see which yields the greatest impact or most accuracy. You can return to the data preparation task to add new variables or redefine existing transformations. The more variations tested, the better the final model.
Creating the best data mining model is a process of triangulation. Attack the data with several algorithms such as decision trees, neural nets and memory-based reasoning. The best-case scenario is when several models point to similar results. This is especially helpful when the tool spits out an answer but doesn't provide an intuitive explanation for it—a notorious problem with neural nets. Triangulation gives all observers (especially business users and management) confidence that the predictions mean something.
There are two kinds of model validation in data mining. The technical approach compares the top models to see which is most effective at predicting target variables. Your data mining tool should provide utilities for comparing the effectiveness of certain types of data mining models. Lift charts and classification (or confusion) matrices are common examples. These utilities run the test data sets through the models and compare the predicted results with the actual, known results.
The business approach to validation involves documenting the contents and performance of the "best" model and conducting a business review to examine its value and verify that it makes sense. Ultimately, model choice is a business decision. The next step is to move the model into the real world.
The Operations Phase
The operations phase is where the rubber meets the road. At this point, you have the best possible model (given time, data and technology constraints) and business approval to proceed. The operations phase involves three main tasks: implementation, impact assessment and maintenance.
At one end of the spectrum, a customer-profiling data mining model that runs once a quarter may only involve the data miner and ETL developer. At the other end of the spectrum, making online recommendations will require applications developers and production systems folks to be involved, which is usually a big deal. If you're working on a big-deal project, include these people as early as possible—preferably during the business phase—so they can help determine appropriate timeframes and resources. It's best to roll out the data mining model in phases, starting with a test version, to make sure the data mining server doesn't affect the transaction process.
Assessing the impact of the data mining model can be high art. In some fields, such as direct mail, the process of tuning and testing marketing offers, collateral and target prospect lists is full-time work for a large team. These teams perform tests on small subsets before they send mass mailings. Even in full campaigns, there are often several phases with different versions and control sets built in. The results of each phase help teams tweak subsequent phases for improved returns. Adopt as much of this careful assessment approach as possible.
Keep in mind that as the world changes, behaviors and relationships captured in the model become outdated. Almost all data mining models must be retrained or completely rebuilt at some point. A recommendation engine that doesn't include the latest products would be less than useful, for example.
Metadata
In the best of all worlds, the final data mining model should be documented with a detailed history. A professional data miner will want to know exactly how a model was created in order to explain its value, avoid repeating errors and re-create it if necessary.
Modern data mining tools are so easy to use, it often takes more time to document each iteration than it does to do the work. Nonetheless, you must keep track of what you have and where it came from. Keep a basic set of metadata to track the contents and derivation of all the transformed data sets and resulting mining models you decide to keep. Ideally, your data mining tool will provide the means for tracking these changes, but the simplest approach is to use a spreadsheet.
For every data mining model you keep, your spreadsheet should capture at least the following: model name, version, and date created; training and test data sets; algorithm(s), parameter settings, input and predicted variables used; and results. Your spreadsheet should also track the definitions of the input data sets, the data sources they came from and the ETL modules that created them.
This approach will help you successfully integrate data mining into your DW/BI system. Remember, the easiest path to success begins with understanding business requirements and ends with delivering business value.
Required Reading |
|---|
The Microsoft Data Warehouse Toolkit: With SQL Server 2005 and the Microsoft Business Intelligence Toolset by J. Mundy and W. Thornthwaite (Wiley, 2006). Data Mining Techniques, Second Edition by M. Berry and G. Linoff (Wiley, 2004). |
Warren Thornthwaite is a member of the Kimball Group. He cowrote The Data Warehouse Lifecycle Toolkit (Wiley, 1998). this column is excerpted from the Microsoft Data Warehouse Toolkit (Wiley, 2006). Write to him at [email protected].
About the Author(s)
You May Also Like
More Insights
Webinars




