

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
The New Deal
A model-driven approach to BI and data warehousing puts analytical power back in step with business requirements.
8 Min Read

Data warehousing arrived 20 years ago to solve a set of problems that, to a large extent, no longer exist. Computing resources were once scarce and prohibitively expensive; dozens of homegrown systems scattered data everywhere and carried their own sets of semantics, business rules, and data management. Businesses simply could not get the information in a timely manner to do reporting, analysis, and planning.
Today, computing resources are practically boundless; though not inexpensive, the cost of servers, networks, and storage as a proportion of total project expenses has dropped dramatically. Data is more organized, in fewer systems, and getting better all the time as a result of general perceptions that it has value beyond the application programs that produce it — and that good data quality and architecture are enterprise requirements. Plus, organizations are benefiting from what the 1990s brought us: not only universal connectivity (the Internet) but also universal information access (the Web).
It stands to reason that, given these fundamental changes in the problem space, the solution set would change as well. But it hasn't. Data warehousing remains stubbornly focused on data and databases instead of information processes, business models, and closed-loop solutions. Methodologies and best practices for data warehousing have barely budged. Our approach to building data warehouses and business intelligence (BI) environments around them is out of step with the reality of today's information technology.
The Truth Hurts
A good example is the notion of a "single version of the truth." Many use this to justify the long, expensive construction of enterprise data warehouses that require person-years of modeling just to get started and extensive development to put into production — and many never get that far. The data warehouse never was a good repository of truth; it is merely a source for downstream applications, which add value to the data through application of formulas, aggregations, and other business rules. In addition, the functional reach of the source systems (such as ERP, customer relationship, and supply chain management) is now so broad that, unlike the operational systems of 20 years ago, much of the "truth" is already contained in and reported from them.
The rigidity of data warehouses endows them with calamitous potential. Current best practices in enterprise systems development call for formal approaches, such as the Zachman Framework. Because the architectures are designed first and then — based on the data modeler's grasp of requirements gathered at the start of the process — rendered into relational data models, organizations burn a version of reality into their data warehouse circuitry right from the beginning.
Unfortunately, no one knows ahead of time what the data warehouse requirements really will be. The gathered "requirements" should be suspect from the beginning. And because relational database data models lack fuller expression, boiling down requirements into one takes us one step further away from a real working business model. A data model cannot capture the subtleties and dynamics of the business. Such designs have the fluidity of poured concrete: that is, only fluid until set. Later, as real requirements begin to emerge, the only choices are to jackhammer designs and start over (rarely happens) or to add more layers of design (data marts, operational data stores, cubes, and so forth), gradually building a structure that is not only expensive and brittle, but also difficult to maintain.
Current methodologies stress the need for iterations: an indication that participants agree that it's not possible to specify a data warehouse all at once. Never, however, is it made clear what's supposed to happen with the previous version of the data model. Or, for that matter, the data models: a layered design like the Corporate Information Factory has no less than seven schema types, and potentially dozens of schemas in the single warehouse. Organizations direct extract, transform, and load (ETL) development against the physical schemas. Most BI tools interact directly with the physical schemas. Does it make sense to have each of the iterations invalidate previous efforts?
Model-Driven Solutions
The alternative is a model-driven architecture. With this approach, the models are not data models; rather, they are expressive business models designed not to just arrange data neatly in a drawer but to solve end-to-end problems. Such models are expressed in terms that are meaningful to stakeholders in the sales, marketing, finance, procurement, product design, engineering, actuarial, auditing, and risk management.
Software tools can capture these models and manage versions, iterations, and other changes directly, also managing the design and redesign of physical objects in the data warehouse. Similarly, a model-driven architecture specifies ETL processes at a level of abstraction rather than to tables and columns, allowing the automated schema managers free range to reconfigure data stores in the most efficient manner (see Figure 1). The data itself may not even be physically mapped from the source systems, as powerful algorithms decide where and when to stage data based on requirements.
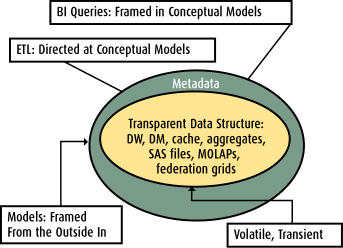
Figure 1 Characteristics of a model-driven architecture.
To be relevant, data warehousing has to shift its focus from excruciating design and architecture to rapid deployment, flexibility and, above all else, connectedness. In the pipeline to support the model-driven approach is a fascinating array of products, some of which are already available. Here are some examples:
Rapid deployment. Two major challenges to delivering BI rapidly are the data modeling process and the integration of typically five or more software tools. An alternative is a single server with all of these services bundled into one product and operating as a unit. Certive's toolset allows businesspeople to build declarative business models in a graphical environment removed from the limitations and arcane concepts of information technology; in turn, the tool builds and modifies the underlying data structures. Another interface leverages the metadata created in the modeling process and provides ETL services. The BI component presents metamodels — not physical structures — to users, and gracefully adapts as the models evolve. Certive's concept is to place modeling in the hands of users, not relational database technicians.
Flexibility. Like Certive, Kalido also employs the concept of declarative modeling and a rich semantic layer to build and modify the physical structures of the data warehouse. Compared to Certive, Kalido's approach is more closely aligned with existing data warehouse technology (especially the underlying relational database). But Kalido's large, multinational customers apply the tool to very large and dispersed data warehouses, offering a single point of change and control. Kalido renders the painful process of modifying the data warehouse's data models into a simple set of manipulations from an administrator's console, imbuing even traditional data warehouses with flexibility and change control not possible previously.
Connectedness. No longer can a data warehouse can be an island unto itself. Older approaches left the data warehouse standing off to the side of enterprise computing: the final resting place of secondhand data. Today, data warehouses must participate with other operational systems, even external ones, as a peer. Designing and maintaining the architecture for that kind of connectedness and interoperability, with the throughput and performance needed, is beyond the current capabilities of most IT departments and data warehouse practitioners. SAP's Business Information Warehouse, as part of SAP BI and the overall NetWeaver architecture, offers a blueprint and set of tools and applications to envelop the data warehouse within the total computing architecture.
The emerging model-driven approach will vastly simplify the design, development and maintenance of data warehouses. Traditional approaches create a partitioned universe — you have either operational or analytical data — that is too rigid for rapid innovation and incapable of providing blended operations and processes that many companies now require.
Model-driven approaches will bring a measure of business sense to data warehousing. In addition, three key improvements will be enabled:
More relevant BI functionality will come through continuous improvement and enhancement. Companies will be able to solve end-to-end problems and propagate BI much more widely.
BI processes will benefit from high-value analytics powered by data depth and breadth. No longer will such analytics be buried in hidden data warehouses, off-limits to business users.
BI will become better integrated with business processes through common understanding and metadata, without the integration layers to navigate.
Pushing through the status quo will be slow because so many industry players have a vested interest. However, two forces for change are already at work. Forward-looking vendors, such as the ones mentioned here, will apply their influence in what has always been a vendor-driven market. Second and most important, leading companies will demand better solutions, especially to provide greater flexibility and connectedness. There's an ocean of unmet need: It's become obvious that current practices cannot address it.
Guest columnist Neil Raden, [[email protected]] is founder of Hired Brains Inc., a consulting, systems integration, and implementation services firm. Based in Santa Barbara, Calif., Raden is a widely published author and speaker on data warehousing, BI, and IT strategy.
Resources
"Stepping Up BI Expectations," Sept. 1, 2003
About the Author
You May Also Like
More Insights




