

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Hortonworks Invests In Spark On Hadoop
Hortonworks improves Hive integration, plans security and performance upgrades for hot Spark in-memory analytics platform.
4 Min Read

10 Big Data Online Courses
10 Big Data Online Courses (Click image for larger view and slideshow.)
There's intense interest in the Apache Spark in-memory platform for big data analytics, and Hortonworks intends to capitalize on it.
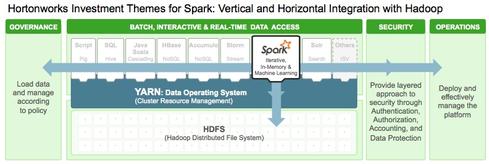
Hortonworks on Wednesday announced that enhanced Hive integration and ORC data-format support for Spark are available immediately through its software, and it also laid out plans to improve Spark security and performance when used in combination with Hadoop by way of YARN resource management.
"Our focus is on ensuring that Spark is YARN-enabled and YARN-optimized, and we also want to make sure that it has the right tools for security and operations," said Jim Walker, Hortonworks' director of product marketing, in a phone interview with InformationWeek.
[Want more on Spark? Read Databricks Spark Plans: Big Data Q&A.]
Developed and promoted by Databricks, Spark is best known for in-memory machine learning (with MLLib), but it also supports SQL analysis (with SparkSQL), streaming analysis (with Spark Streaming), and is expected to support the popular R analytics library and graph analysis (with SparkR and GraphX, respectively). Spark can run as a standalone, distributed cluster, but it also runs on Hadoop and Cassandra and can tap into MongoDB and conventional relational database sources.
Hortonworks is interested in making Spark work better with Hadoop, so it has written and contributed code to Spark that improves integration with Hive, the Hadoop-native, open-source SQL query tool that Hortonworks favors. (Hortonworks competitors also ship Hive, but Cloudera promotes its proprietary Impala SQL query engine while MapR supports open-source Apache Drill.)
Hortonworks says its new code, available this week as tech previews from its website, specifically improves Spark's ability to read and write data stored in Hive. This includes data written in Optimized Row Columnar (ORC), a columnar storage format optimized for both read performance and data compression that is, according to Hortonworks, rapidly becoming the de facto storage format for Hive.
Databricks might point out that SparkSQL is not dependent upon Hive or any other SQL-on-Hadoop option to query against Hadoop or, indeed, other sources. SparkSQL can take advantage of Hive metadata, but it's a SQL-on-multiple-sources option in its own right with its own metastore and ability to infer schema directly from data, whether in Hadoop, conventional databases, Cassandra or MongoDB. One caution: SparkSQL is an Alpha release within a 1.0 platform, so it's not exactly mature -- despite numerous production deployments Databricks might cite.
The other points of Spark maturation in the works at Hortonworks include security and operational improvements. Specifically, access control via LDAP or Active Directory and management of Spark components via the open-source Ambari management console are expected to be available by year's end. The first provides obvious and familiar security controls, while the latter will enable admins to install, start, stop, and configure Spark components with the same interface used to manage Hortonworks Hadoop clusters.
In a second phase of Spark optimization, Hortonworks says it's investing in enhancements that will improve the reliability and scalability of Spark on YARN. Spark already supports YARN, but Hortonworks says it's working on improving resource utilization so that Spark does a better job of releasing memory and compute resources. Being an in-memory platform, Spark is particularly dependent upon available memory resources.
"We have to make sure that Spark is a good citizen within a multi-engine cluster," said Walker. "What we've seen with Spark, and with other engines in the past, is that it sometimes takes over resources and will not release them until all jobs that it needs to complete are done."
In addition to working on releasing resources as available, Hortonworks is also developing ways for YARN to assign memory-intensive nodes and faster storage options for use by Spark, Walker said.
The second phase of improvements will also include improvements in Spark debugging, data-encryption, and data-access authorization, as well as integration of Spark with YARN's Application Timeline Server, which will yield better visibility into the health and execution status of Spark engines and workloads. All second-phase improvements are expected to be delivered in the first half of 2015.
Hortonworks is just one of 10 companies distributing Spark software. The others include BlueData, Cloudera, DataStax, Guavus, IBM, Oracle, Pivotal, SAP, and Stratio. Three of these distributors, Cloudera, DataStax, and MapR, are certified by Databricks as support providers. Hortonworks says it's already supporting the Spark software it ships even though Databricks certification is still in the works.
What will you use for your big data platform? A high-scale relational database? NoSQL database? Hadoop? Event-processing technology? One size doesn't fit all. Here's how to decide. Get the new Pick Your Platform For Big Data issue of InformationWeek Tech Digest today. (Free registration required.)
About the Author
You May Also Like
More Insights




