

Never Miss a Beat: Get a snapshot of the issues affecting the IT industry straight to your inbox.
Splice Machine SQL Database Scales On Hadoop
Splice Machine promises SQL- and ACID-compliant RDBMS for analytics and transaction processing on a super-scalable, low-cost Hadoop platform.
5 Min Read


10 Hadoop Hardware Leaders
10 Hadoop Hardware Leaders (Click image for larger view and slideshow.)
Promising the best of both worlds, startup Splice Machine last week announced the latest stab at putting SQL on Hadoop, but this time it's a fully SQL-compliant and ACID-compliant relational database management system (RDBMS) on Hadoop that's not just for analytics.
"Splice Machine can replace Oracle, Microsoft SQL Server, IBM DB2, or MySQL, where those systems might hit the wall from a performance or cost perspective," said Monte Zweben, CEO of Splice Machine, in a phone interview with InformationWeek.
Hadoop provides the scale-out technology for Splice Machine, so it runs on scalable, commodity clusters. At the same time it's compatible with existing investments in SQL-based business intelligence software, ETL systems, and applications through an ODBC/JDBC driver.
[Want more on Hadoop options? Read Pivotal Subscription Points To Real Value In Big Data.]
Several databases have been ported to run on top of Hadoop, including Pivotal's Greenplum database (through HAWQ) and InfiniDB, but these are specialized databases designed for high-scale querying and analysis. Splice Machine, which marries the open-source Apache Derby Java-based database with Hadoop's HBase NoSQL database, touts RDBMS-speed transaction processing.
"Our unique differentiation is that we're the only [SQL-on-Hadoop option] that can support concurrent reads and writes in a transactional context with ACID compliance," says Zweben.
Splice Machine uses a concurrency control method called "snapshot isolation" in combination with HBase, which has ACID properties over updates in a single table. The Apache Derby SQL planner and optimizer have been extended to take advantage of Hadoop's parallel architecture, according to Zweben. As plans are executed on each node, they're spliced back together -- thus the name of the company.
Figure 1: 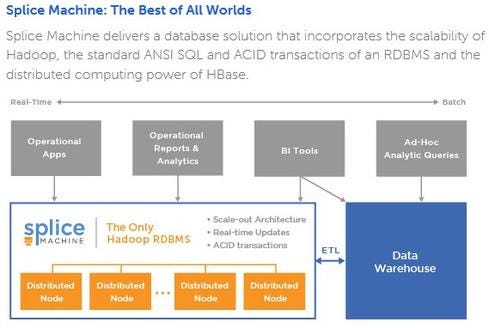
"We started with two well established open-source stacks, Derby and Hadoop, and that's one of the reasons we can come to market so quickly," says Zweben. Splice Machine was founded in 2012.
With last week's introduction, Splice Machine entered public beta, but the company says it has 15 charter customers in industries including digital marketing, telecom, and high-tech. One of those customers is well known marketing services firm Harte Hanks, which has been testing Splice Machine since last summer.
Harte Hanks is poised to replace Oracle RAC in a campaign-management application that combines IBM Unica, IBM Cognos reporting, Ab Initio data-integration software, and Trillium data-cleansing technologies. All of the above are designed to run on or work with SQL RDBMSs, so moving the app onto Hadoop or
a NoSQL database was out of the question. At the same time, running Oracle RAC for a series of 10-terabyte to 20-terabyte instances for each Harte Hanks customer was getting to be expensive.
"We have a lot of investment in things that run on SQL, including Cognos, Unica, ETL work, data cleansing, customer roll-ups and models, and staff that are doing analytics with SAS and SPSS," said Robert Fuller, managing director of product innovation at Harte Hanks, in a phone interview with InformationWeek. "With Splice Machine we can still work with all that, but we're getting the benefits of Hadoop scaling and performance as well as lower-cost hardware and lower-cost software."
By way of comparison, Fuller said adding six nodes to a Hadoop cluster requires $25,000 worth of hardware, whereas adding equivalent capacity with Oracle RAC and a separate storage area network would cost more than $100,000 just for the hardware. Add the software licenses, and "you're not doubling or tripling the cost, you're ten times the cost."
Splice Machine last summer demonstrated in its own labs that it could run the Harte Hanks applications and beat Oracle RAC performance. By the end of last year, Harte Hanks built out a Cloudera cluster and proved that it could replicate that performance using customer data in its own datacenters.
"One of the common campaign-performance queries that we've tested takes about 183 seconds in our production Oracle RAC deployment, and it's taking less than 20 seconds on Splice Machine on a nine-node Cloudera cluster," says Fuller.
The next step for Harte Hanks is to build out replication and high-availability features and take Splice Machine into production. Fuller has not had to hire new staff to learn how to deploy and use Hadoop thus far, but that may change, he says, when Harte Hanks starts taking advantage of MapReduce processing, as well as SQL OLTP and analysis on top of Hadoop.
The next step for Splice Machine hinges in part on the pending 1.0 release of HBase, says Zweben, noting that this foundation of the Hadoop ecosystem is still at the 0.95 release stage. Splice Machine 1.0 will be generally available sometime this year, he vows, but he notes that the Splice Machine public beta release now available for download is suitable for production deployment.
"HBase powers RocketFuel, a company that handles on the order of 15 petabytes of advertising optimization data a day," says Zweben, who is a member of RocketFuel's board of directors. "Our beta system is ready to be put into operation today."
Splice Machine's apparent success in doing it all on Hadoop makes one wonder if the commercial database incumbents can and will follow suit.
Our InformationWeek Elite 100 issue -- our 26th ranking of technology innovators -- shines a spotlight on businesses that are succeeding because of their digital strategies. We take a close at look at the top five companies in this year's ranking and the eight winners of our Business Innovation awards, and offer 20 great ideas that you can use in your company. We also provide a ranked list of our Elite 100 innovators. Read our InformationWeek Elite 100 issue today.
About the Author
You May Also Like
More Insights




